# A tibble: 6 × 9
species date geo_group region losses dead discarded escaped other
<chr> <date> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 salmon 2020-01-01 area 1 31425 28126 3299 0 0
2 salmon 2020-01-01 area 2 324116 277888 46113 0 115
3 salmon 2020-01-01 area 3 844829 776983 63770 0 4076
4 salmon 2020-01-01 area 4 676852 623159 51823 0 1870
5 salmon 2020-01-01 area 5 109269 97627 11424 0 218
6 salmon 2020-01-01 area 6 548921 531193 15710 0 2018Working smarter with dplyr 1.2.0
R-Ladies Rome | Isabella Velásquez
Introduction

Introduction
⬢ Slides available at: https://ivelasq-dplyr-1-2-0.share.connect.posit.cloud
⬢ Links available at the end of the slide deck

![]()
Salmonid Mortality Data from TidyTuesday
⬢ Salmonid mortality datasets published by the Norwegian Veterinary Institute
⬢ Two datasets are shared, the monthly mortality data, and the monthly loses data
⬢ Data from 2020

Quick review of dplyr functions
arrange() changes the ordering of the rows

Quick review of dplyr functions
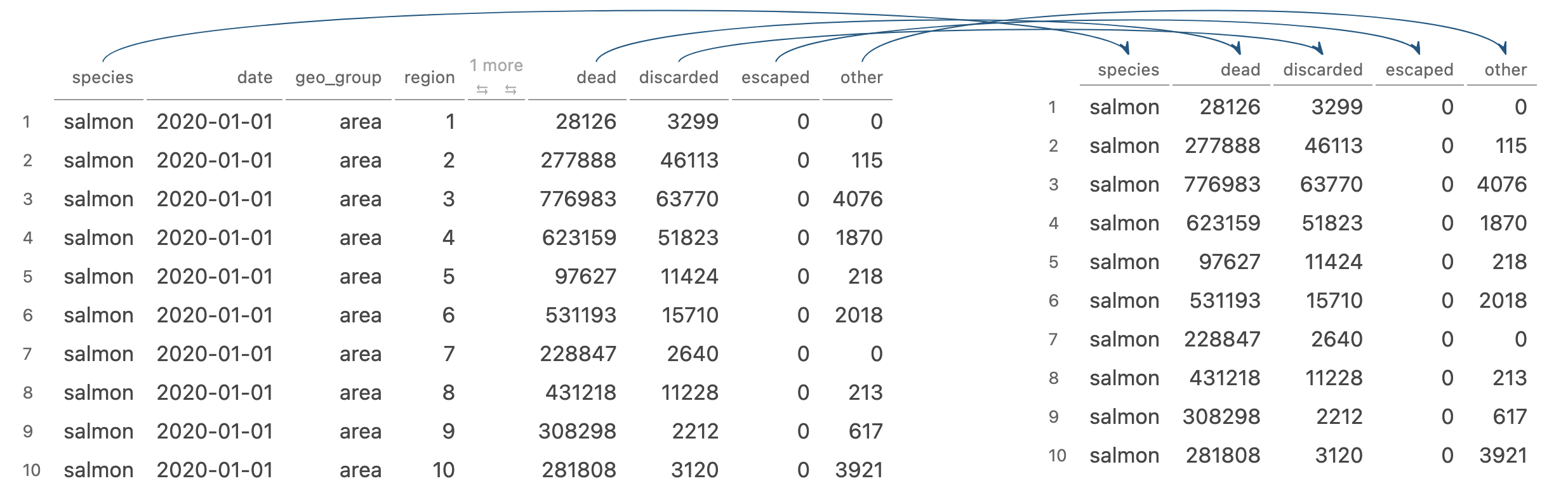
select() picks variables based on their names
Quick review of dplyr functions
summarise()/summarize() reduces multiple values down to a single summary

Quick review of dplyr functions
group_by() allows you to perform any operation “by group”

Quick review of dplyr functions
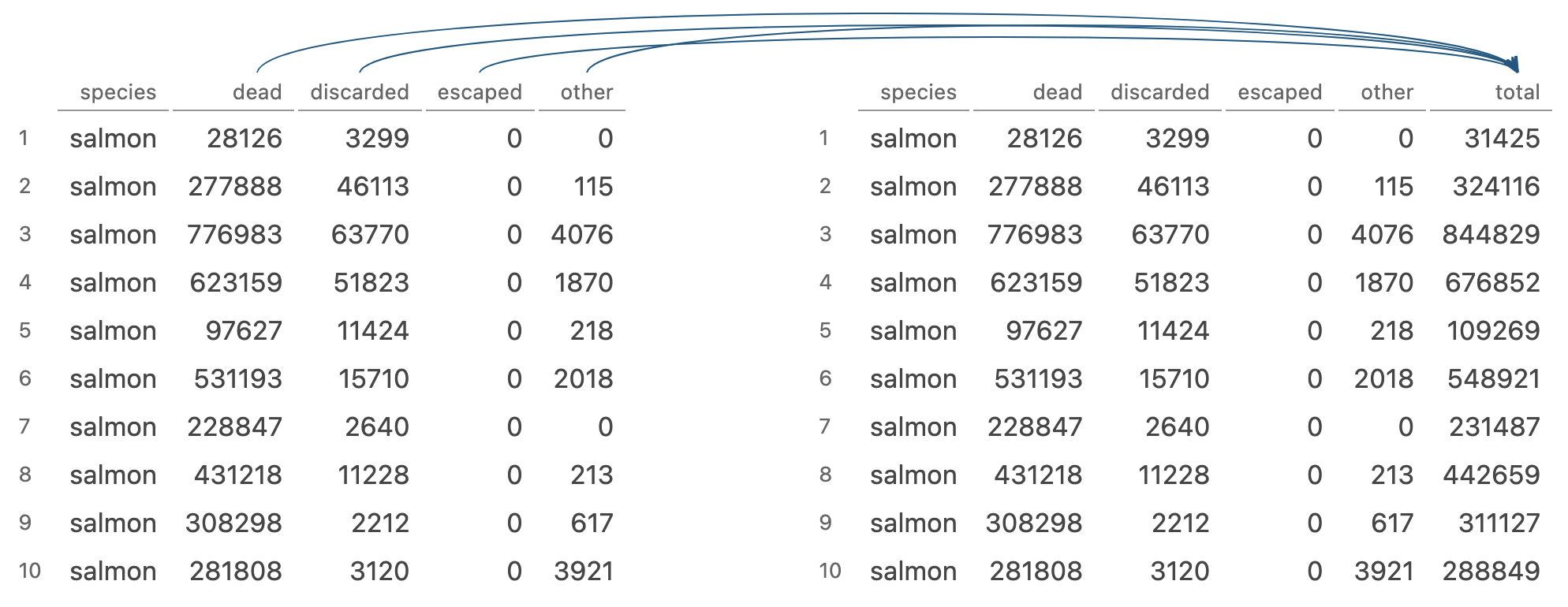
mutate() adds new variables that are functions of existing variables
Quick review of dplyr functions
case_when() checks each condition in order and uses the first match to determine the value of a new variable

Quick review of dplyr functions
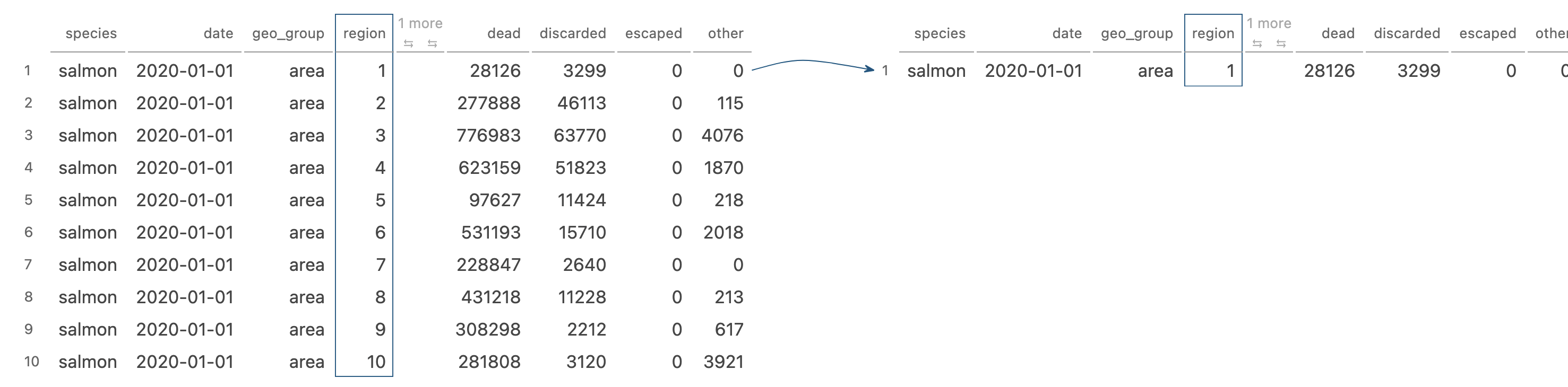
filter() picks cases based on their values
The problem with using filter() to exclude
Drop rows where region is 3 and losses are greater than 700,000.
# A tibble: 5 × 3
species region losses
<chr> <chr> <dbl>
1 salmon 1 31425
2 salmon 2 324116
3 salmon 3 844829
4 salmon 3 676852
5 salmon 3 NA![]()
The problem with using filter() to exclude
To properly use filter(), we would need to do something like:
# A tibble: 4 × 3
species region losses
<chr> <chr> <dbl>
1 salmon 1 31425
2 salmon 2 324116
3 salmon 3 676852
4 salmon 3 NA
Work smarter with filter_out()
Now, we just have to run:
# A tibble: 4 × 3
species region losses
<chr> <chr> <dbl>
1 salmon 1 31425
2 salmon 2 324116
3 salmon 3 676852
4 salmon 3 NA
Issues with using filter() and |
Keep rows where region 7 or 8 have losses over 400,000 OR and where regions 2 or 9 have losses over 300,000.
# A tibble: 8 × 3
# Groups: region [4]
species region losses
<chr> <chr> <dbl>
1 salmon 2 324116
2 salmon 2 197239
3 salmon 7 231487
4 salmon 7 475115
5 salmon 8 442659
6 salmon 8 327323
7 salmon 9 311127
8 salmon 9 286601![]()
![]()
![]()
![]()
Issues with using filter() and |
Keep rows where region 7 or 8 have losses over 400,000 OR and where regions 2 or 9 have losses over 300,000. In this case, Rows 1, 4, 5, and 7)
# A tibble: 4 × 3
# Groups: region [4]
species region losses
<chr> <chr> <dbl>
1 salmon 2 324116
2 salmon 7 475115
3 salmon 8 442659
4 salmon 9 311127
Work smarter with filter() + when_any()
# A tibble: 4 × 3
# Groups: region [4]
species region losses
<chr> <chr> <dbl>
1 salmon 2 324116
2 salmon 7 475115
3 salmon 8 442659
4 salmon 9 311127
Work smarter with filter() + when_all()
# A tibble: 2 × 3
# Groups: region [2]
species region losses
<chr> <chr> <dbl>
1 salmon 7 475115
2 salmon 8 442659
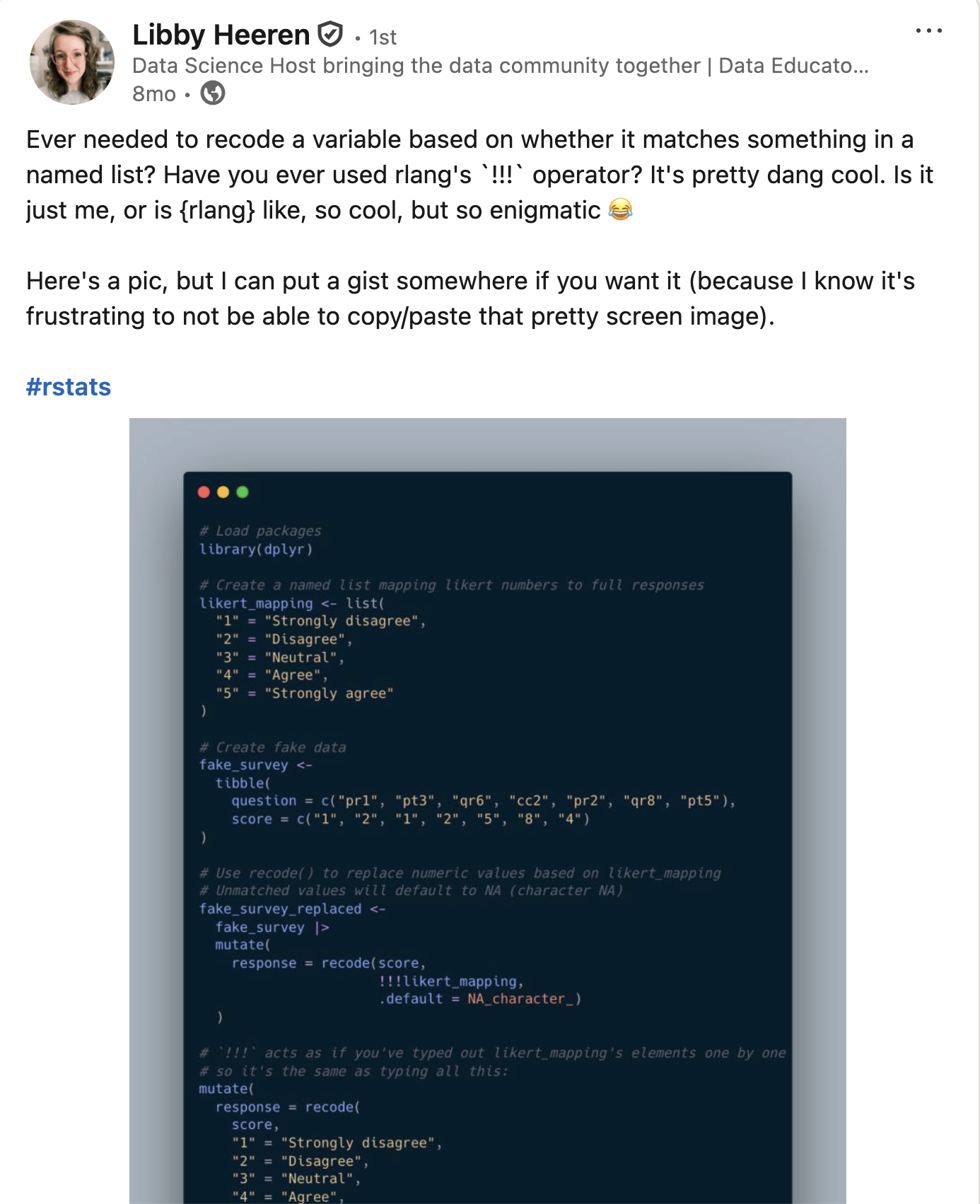
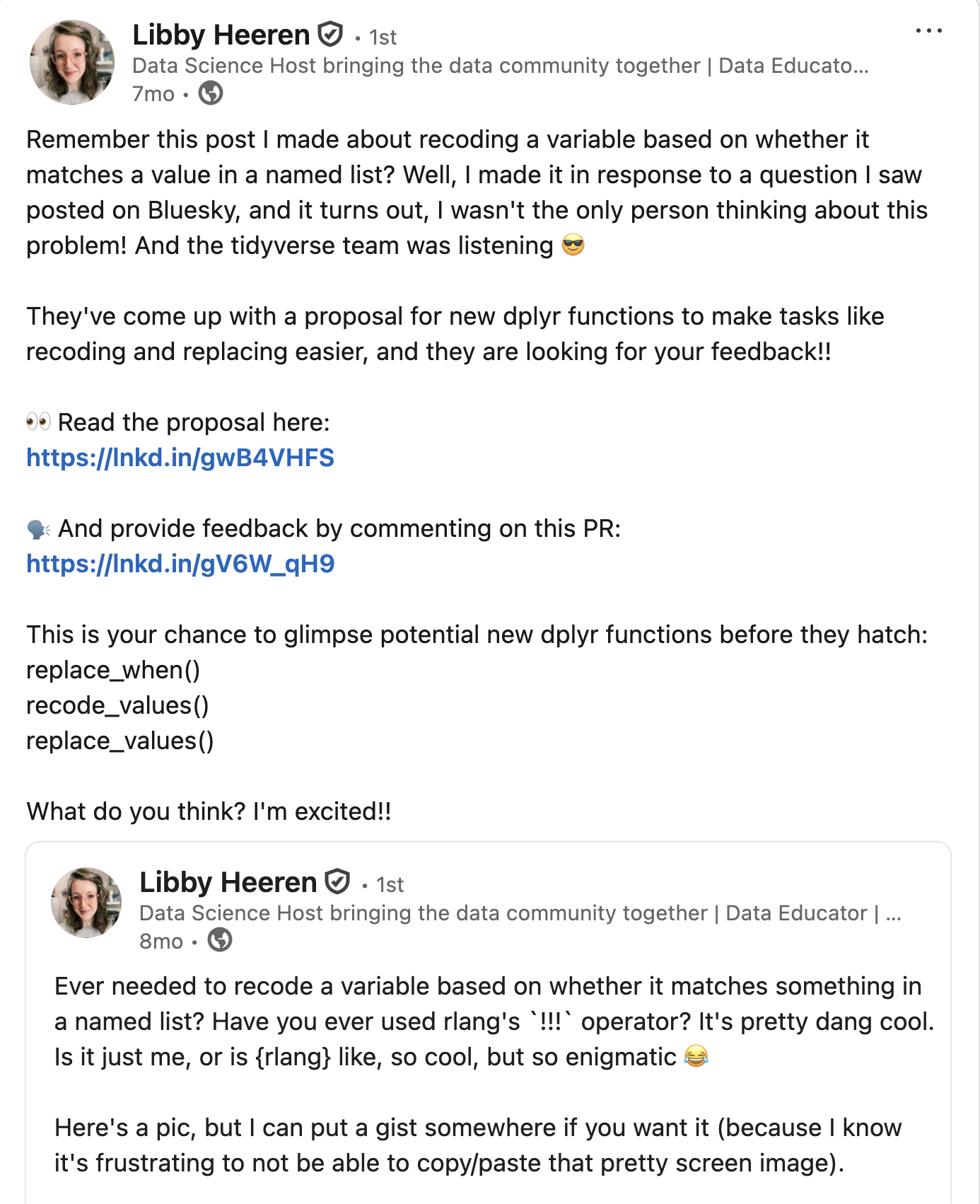
Recoding has always been a pain
case_match() has been soft deprecated

Community feedback is sooo important
Installing dplyr 1.2.0
Upgrade today!
